Automatic
Building Extraction in Aerial Scenes
Using Convolutional Networks
Jiangye Yuan
Up-to-date maps of
buildings are critical for a wide range of applications from navigation
to population estimation. Remote sensing imagery provides an ideal data
source for creating such maps, but manually delineating buildings on
images is notoriously time and effort consuming. We present a new
building extraction approach by training a deep convolutional network
with building footprints from existing GIS maps.
Methodology
An integration stage:
We design a
convolutional network with a
special stage
integrating
feature maps from multiple preceding
stages, as shown below. In particular, feature maps from a stage are
branched and upsampled to larger sizes. 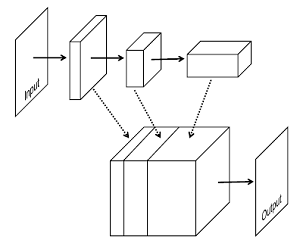
Upsampled feature maps
are
stacked together and fed into single layer perceptrons, which is
equivalent to a 1-by-1 convolutional layer, to achieve pixel-wise
prediction. The network takes input of arbitrary sizes, and processes
images in an end-to-end manner.
Output representation:
Building extraction
results can be represented in two common ways,
boundary maps (middle-left in the figure below) and region maps (middle
right). However, both representations have inherent deficiencies.
Training with boundary maps essentially discards information of whether
pixels are inside or outside buildings. Region maps cannot represent
boundaries of adjacent buildings, which can be neither exploited during
training nor detected in test. We use the signed distance function
(right). The signed distance function value at a pixel is equal to the
distance from the pixel to its closest point on boundaries with
positive indicating inside objects and negative otherwise. There are
two advantages. 1) Boundaries and regions are captured in a single
representation and can be easily read out (boundaries are zeros and
regions are positive values). 2) Training with this representation
forces a network to learn more information about spatial layouts (e.g.,
the difference
between locations near buildings and those far away).
Network
training and results
The network we use
contains seven regular ConvNet stages
and a final stage for pixel level classification. We use a
collection of aerial
images with RGB bands at 0.3 meter resolution covering the D.C. area
and the corresponding building footprint layer downloaded from a public
GIS database. We compile a
training dataset consists of 2000 image tiles of 500*500 pixels and the
corresponding
building masks, and a test dataset containing
images covering areas excluded from the training data. The network
is trained on a single GPU for two days. Two example results are shown
below.
These are raw output of network without any post-processing.
Transparent red corresponds to positive values (regions), and blue
values around zeros (boundaries).

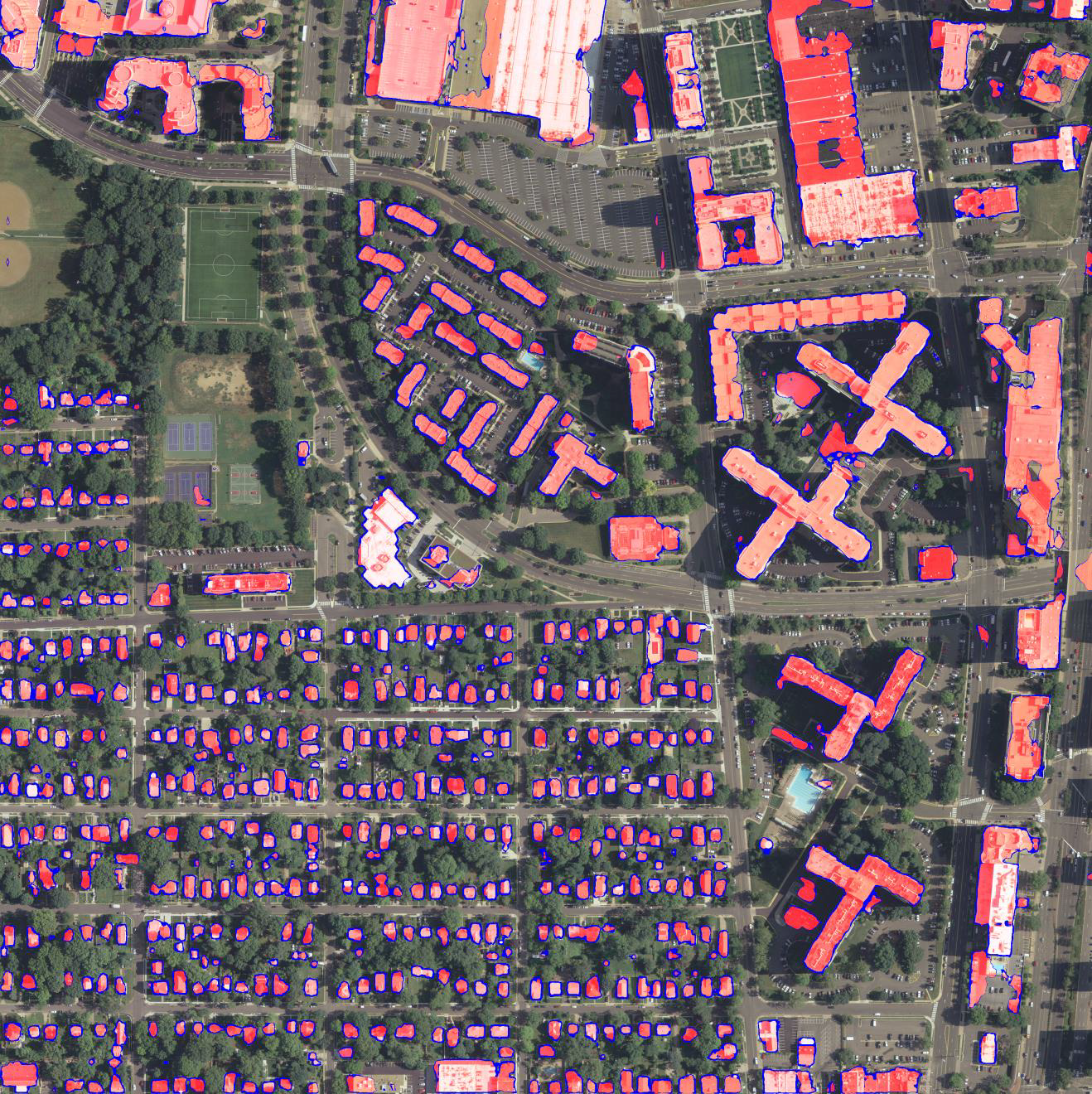
Another benefit of using
distance representation is that individual buildings can be better
separated by applying larger thresholds to predicted distance
values. In the example below, a threshold of 2 gives a good separation
of tightly connected buildings.
Please
refer to the
following papers for details.
Jiangye Yuan, Automatic
Building Extraction in Aerial Scenes Using Convolutional Networks, arXiv:1602.06564, 2016. [pdf]
Jiangye Yuan, Learning Building Extraction in Aerial Scenes with Convolutional Networks, TPAMI, 2017